Disposer de données prêtes à être exploitées par l’IA est indispensable pour valoriser vos efforts dans ce domaine. Il est important de savoir ce que cela signifie et de suivre les cinq étapes suivantes pour s’y préparer.
- Client Gartner ? Log in pour des résultats de recherche personnalisés.
Qu’entendons-nous par des données prêtes au traitement par l’IA ? Et comment assurer la bonne préparation de vos données
Par Rita Sallam | 21 octobre 2024

{kind=link}
Les données prêtes au traitement par l’IA doivent répondre à des exigences spécifiques ; suivez une feuille de route qui vous permettra de respecter certaines dispositions
Les responsables d’analyses de données doivent démontrer que les données de leur entreprise sont prêtes à être exploitées dans le cadre d’un nombre de projets impliquant l’IA toujours croissant, mais il existe des différences considérables entre les exigences liées à l’obtention de données prêtes à un traitement par l’IA et la gestion de données traditionnelles. Pour pallier à ces différences, Gartner recommande de suivre les étapes suivantes :
Évaluez vos besoins en données en fonction des applications de l’IA envisagées.
Présentez ces besoins au conseil d’administration et obtenez son adhésion.
Adaptez les pratiques de gestion des données.
Développez l’écosystème de gestion des données.
Faites évoluer et administrez les données.
Cette feuille de route assurera que vos données sont prêtes à être utilisées dans les projets d’IA que vous envisagez de poursuivre et permettra aux parties prenantes de bien comprendre les implications réelles de la préparation des données à l’IA.
Le contenu suivant pourrait également vous intéresser : Consultez Se préparer à exploiter l’IA : ce que les responsables informatiques se doivent de connaître et entreprendre pour en savoir plus sur le recensement des applications de l’IA.
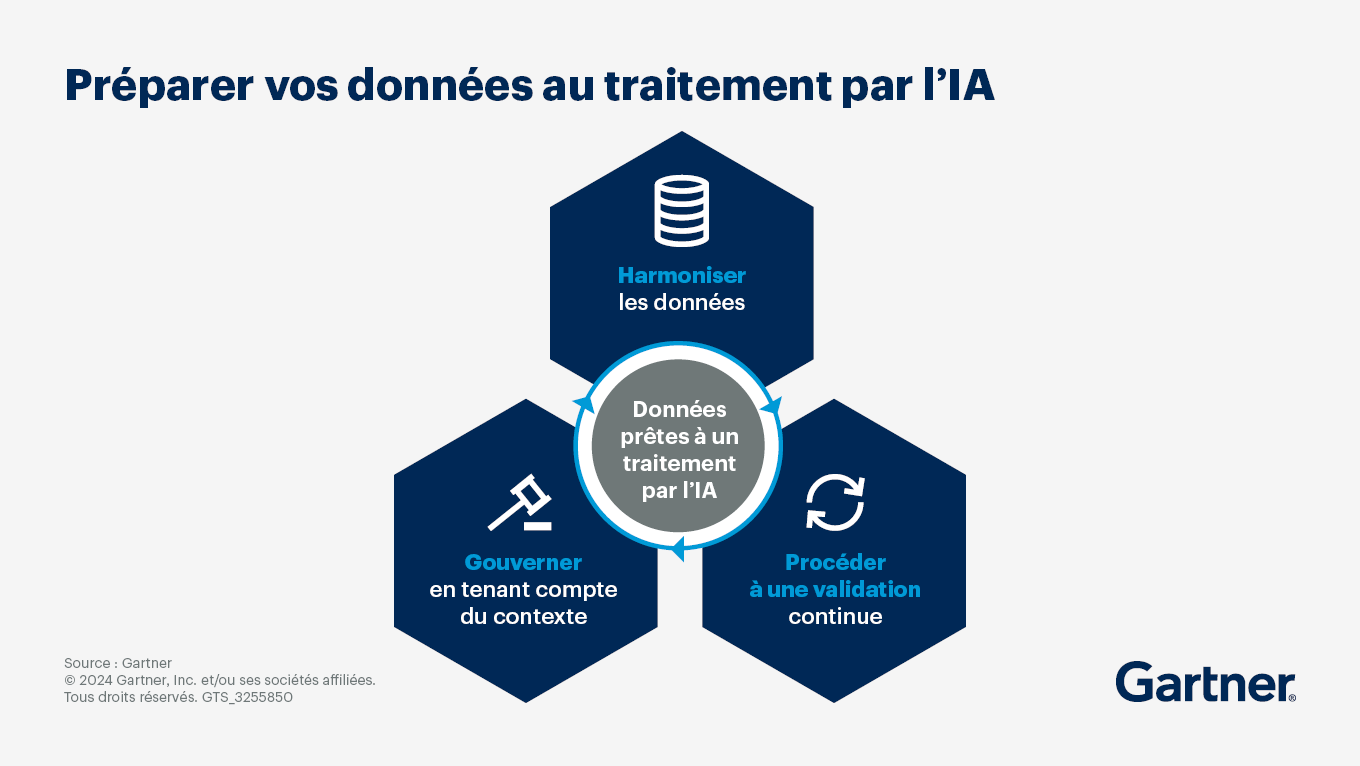
Qu’entendons-nous par des données prêtes à un traitement par l’IA ?
Vous pouvez démontrer que vos données sont prêtes à répondre aux exigences de l’IA en les adaptant aux différentes applications, en les validant et en mettant en place une gouvernance appropriée. Il peut être utile de se poser les trois questions suivantes.
Les données de notre entreprise sont-elles conformes aux exigences des applications ?
Chaque scénario d’utilisation de l’IA doit préciser la nature des données dont il a besoin, qui dépendra par ailleurs du type d’IA utilisé. Il se peut que ces exigences ne soient pas entièrement identifiées initialement, mais elles deviendront évidentes au fur et à mesure que les données seront exploitées et que les exigences relatives à l’IA seront satisfaites. Examinez plus en détail les exigences, telles que :
Les techniques d’IA : les différentes techniques d’IA, telles que l’IA générative (GenAI) ou les modèles de simulation, ont des exigences particulières en matière de données.
La détermination du volume de données : veillez à ce que le volume de données soit suffisant, en tenant compte de caractéristiques telles que la saisonnalité.
La sémantique et le marquage : une annotation et un étiquetage appropriés sont essentiels, en particulier pour les images et les vidéos.
La qualité : les données doivent répondre à des normes de qualité spécifiques au cas d’utilisation de l’IA, même si elles comportent des erreurs ou des valeurs aberrantes.
La confiance : les sources et les flux de données doivent être fiables.
La diversité : inclure des sources de données diverses pour éviter les biais.
La traçabilité : maintenir la transparence sur l’origine et la transformation des données.
Comment évaluer l’utilisation des données pour répondre aux exigences de fiabilité souhaitées de l’IA ?
La validation de cette utilisation permet de s’assurer que les données répondent en permanence aux exigences, que ce soit pour assurer l’apprentissage, le développement ou l’exécution d’un modèle dans le cadre des opérations. Utilisez les paramètres suivants pour vous assurer que les données répondent aux exigences de fiabilité attendues des applications de l’IA :
Validation et vérification : assurez-vous régulièrement que les données répondent aux exigences au cours du développement et des opérations.
Performance et coût : les données doivent respecter les accords de niveau de service opérationnel, y compris en ce qui concerne le temps de réponse et le rapport coût-efficience.
Versions : assurez le suivi et la gestion des différentes versions des données afin de faire face à la dérive des modèles et aux problèmes liés aux flux de données.
Tests de régression continus : élaborez des procédures de test pour détecter toute erreur et dérive au niveau des données.
Mesures d’observabilité : surveillez l’intégrité des données, y compris leur fourniture en temps voulu et leur exactitude.
Comment gouverner des données adaptées à un traitement par l’IA en fonction de l’utilisation qui en est faite ?
Définissez les exigences continues en matière de gouvernance auxquelles les données doivent répondre pour répondre à l’application envisagée de l’IA, en utilisant les paramètres suivants :
Gestion des données : appliquez les politiques nécessaires tout au long du cycle de vie des données, y compris celles qui concerne l’accès au modèle et au développement.
Normes et réglementations : respectez les réglementations en matière d’IA qui ne cessent d’évoluer, telles que le Règlement européen sur l’intelligence artificielle et le RGPD.
Éthique de l’IA : prenez en compte les considérations éthiques, comme l’utilisation de données de clients réels pour l’entraînement du modèle.
Inférence et dérivation contrôlées : suivez la façon dont les modèles interagissent et assurez la gouvernance.
Biais dans les données et équité : gérez les biais des données de manière proactive et testez les modèles avec des ensembles de données antagonistes.
Partage des données : facilitez le partage des données et des métadonnées pour répondre aux différentes utilisations de l’IA.
En savoir plus sur les étapes clés de la feuille de route pour préparer les données au traitement par l’IA.
En s’appuyant sur des interactions étroites avec des clients qui ont mis en œuvre avec succès des projets de préparation des données afin de faciliter leur traitement par l’IA, Gartner recommande cinq étapes aux responsables des analyses de données pour préparer leurs données.
Évaluer l’état de préparation de la gestion des données : évaluez l’état actuel de vos pratiques de gestion des données afin d’identifier les lacunes et les points à améliorer.
Obtenir l’adhésion du conseil d’administration : obtenez le soutien et l’approbation de la direction pour garantir la disponibilité des ressources et la mobilisation indispensables aux programmes d’IA.
Faire évoluer les pratiques de gestion des données : adaptez et améliorez vos stratégies de gestion des données pour répondre aux exigences spécifiques des données prêtes au traitement par l’IA.
Enrichir l’écosystème de données : développez votre infrastructure de données et vos capacités pour prendre en charge des utilisations de l’IA diverses et évolutives.
Mettre à l’échelle et gouverner : mettez en œuvre des cadres de gouvernance des données solides pour garantir la qualité, la conformité et l’utilisation éthique des données à mesure que vos projets d’IA prennent de l’ampleur.
FAQ sur les données prêtes au traitement par l’IA
Que sont les données prêtes au traitement par l’IA ?
Les données prêtes au traitement par l’IA sont des données qui doivent être représentatives du cas d’utilisation, et de chaque modèle, erreur, valeur aberrante et émergence inattendue qui est nécessaire pour former ou faire fonctionner un modèle d’IA dans le cadre d’une utilisation spécifique. Il s’agit d’un processus et d’une pratique fondés sur la disponibilité de métadonnées permettant d’harmoniser, de valider et de gouverner les données.
Comment faire en sorte que toutes nos données soient prêtes à un traitement par l’IA ?
Il n’existe aucun moyen de préparer de manière globale ou à l’avance les données à un traitement par l’IA. Le degré de préparation des données au traitement par l’IA dépend de la manière dont les données seront utilisées. Par exemple, pour créer un algorithme de maintenance prédictive, il faudrait des ensembles de données très différents de ceux nécessaires à l’application de l’IA générative aux données des entreprises.
Si nos données sont de haute qualité, sont-elles pour autant prêtes au traitement par l’IA ?
Des « données de haute qualité », telles que définies par les normes traditionnelles de qualité des données, ne sont pas pour autant synonymes de données prêtes à un traitement par l’IA. Si l’on considère les données dans le contexte de l’analyse, par exemple, on s’attend à ce que les valeurs aberrantes soient supprimées ou que les données soient corrigées pour répondre aux attentes des humains. Pourtant, lors de l’entraînement d’un algorithme, ce dernier aura besoin de données représentatives. Cela peut également inclure des données de mauvaise qualité.